Feeling like I’d burned through my standard sources for movie recommendations, I recently decided to turn to box office failures. I was seeking out an automated way to explore the world of such movies and find “overlooked” films that are actually very good, but were ignored in theaters and dismissed by critics.
Using Nathan Rabin’s popular “My Year of Flops” series on The AV Club and follow-up book as a starting point, I designed an algorithm to predict whether a box office failure is actually a film worth seeing. The algorithm examines multiple aspects of a movie’s cultural response to make its prediction – such as applying sentiment analysis to capture the tone of reviews, and understanding whether critics and audiences responded differently to a movie. The output is a list of 100+ movies released over the past decade with high likelihood of being quality, “overlooked” films.
Here’s how it works…
THE POWER OF “OVERLOOKED” FILMS.
In 1994, Forrest Gump made over $300M at the domestic box office, won six Oscars, and spawned a murderer’s row of pop culture references.
The Shawshank Redemption also came out that year. It had a confusing name, won exactly zero Oscars, and made only $16M in its initial run – an amount outdistanced by House Party 3, Kid ‘n Play’s capstone installment in their “living-situation-oriented festival” trilogy.
Yet flip on TNT on a random Saturday night, and you’re more likely to be greeted by Andy and Red than by Forrest and Jenny.
Because it flopped in theaters, people had to discover Shawshank organically on video. And not only did its reputation grow, but fans felt a sense of personal ownership and evangelism. Nearly everyone I know who’s seen the movie first watched it because of a recommendation, and fiercely loyal IMDb users have even rated it the best movie of all time.

There’s a special power to great films that people have to discover – to the quality movies that bombed (or even simply disappointed) at the box office while still in theaters.
People want to talk about these types of movies, often even more so than movies that are equally good but more well-known. Unlike hit movies that already have high awareness, “overlooked” movies make you want to tell your friends with a sense of urgency – “You have to check this out, trust me.” When you told your friends to see Office Space, or Zoolander, you were helping someone find something great that they never would have known about. You were growing the pop culture pie.
So why is it so hard to actually discover these overlooked films? Well, the reality is that most flops are flops for a reason – they aren’t very good. Who wants to spend an afternoon gutting through scenes like this to find out if Catwoman is actually a worthwhile film?
(Spoiler alert: No, it isn’t. It’s a terrible, terrible film.)
ENTER NATHAN RABIN’S “MY YEAR OF FLOPS” SERIES.
Fortunately, one man has given us a head start. In his “My Year of Flops” AV Club columns (and follow-up book), Nathan Rabin gave a second chance to forgotten, ignored, and/or reviled films throughout cinematic history. Our Waterworlds, our Giglis, our Battlefield Earths.
But rather than simply snark his way through each movie, his goal was to honestly re-evaluate each film on its own merits, and even identify flashes of greatness, if any exist.
At the conclusion of each review, a film is rated into one of three categories:
- “Secret Success” – a genuinely good movie.
- “Failure” – a genuinely bad movie.
- “Fiasco” – a movie that can’t really be called “good”, but at least reaches, epically and messily, for goodness. In Rabin’s estimation, a Fiasco is actually preferable to and more enjoyable than a pure Failure.
This categorization ends up producing something more complex and subtle than simply looking for good movies by, say, Rotten Tomatoes score alone.

Note that while Secret Successes are, naturally, reviewed the most favorably, the average Secret Success would still receive a “Rotten” rating on Rotten Tomatoes. Thus, using Rotten Tomatoes freshness rating alone would miss a great number of movies that Rabin’s re-evaluation judged to be quite good.
(The way to interpret this is that cases like Shawshank are actually relatively rare – a movie that highly regarded [90% on Rotten Tomatoes] usually gets quite a bit of attention, and soon ceases to be “overlooked”. Much more common is the case when a genuinely enjoyable movie either hits a cultural tidal wave, or comes with critical baggage that weighs down its score.)
(Zoolander is a case of the former; its 64% Rotten Tomatoes score and disappointing box office performance are understandable given its release in late September 2001. The Hudsucker Proxy is an example of the latter, suffering in comparison to the rest of the Coen brothers’ magnificent body of work, as the reviews accompanying its 56% rating make clear.)
Also, note that Fiascoes are rated more highly than Failures — an interesting validation of Rabin’s rationale for splitting the two.
The problem, of course, is that Nathan Rabin is just one man. Even after 200+ films and a spinoff “My World of Flops” series, he isn’t capable of seeing and judging all the box office disappointments out there.
In startup parlance, he “doesn’t scale.”
To evaluate the films that he wasn’t able to, I used the films in the “My Year of Flops” series as an initial dataset to train a machine learning classifier that could “teach” itself patterns that separate a Secret Success from a Failure from a Fiasco. With such a system, the thankless task of evaluating movies and fetching high-potential candidates can now be outsourced to a machine.
WHAT CHARACTERISTICS DO SECRET SUCCESSES HAVE IN COMMON?
One of the most useful aspects of supervised machine learning was that I could feed in dozens of pieces of information about 180+ movies from the “My Year of Flops” series, and let the system figure out for itself which information was actually predictive of a film’s rating.
And as it turns out, if you want to know if a movie is a Secret Success, a Fiasco, or a Failure, then the intrinsic qualities of a film aren’t all that helpful. You don’t need to know a movie’s stars, or the director, or the genre or runtime or budget or amount of pre-release press. Instead, if you’re seeking patterns among Secret Successes, Fiascoes, and Failures, you’re better off looking at how critics and audiences described a movie.
In retrospect, this makes sense. After all, the intrinsic aspects of a movie are incredibly complex, interrelated, and unpredictable. Movies can’t be reduced to a basic set of building blocks that ensure a quality output — in the words of legendary screenwriter William Goldman, in the movie industry “nobody knows anything.” External responses, however, present a richer, more coherent set of data to mine through – hundreds of reviews vs a handful of actors, the aggregate opinion of thousands of casual movie viewers vs a single director – and is a more logical place to search for useful patterns.

Three aspects in particular emerged as useful:
- Critical Response – Was the movie regarded well or poorly by critics?
- This is captured by the normalized measure of a film’s Rotten Tomatoes Critics Score. All else equal, a high score indicates a Secret Success and a low score indicates a Failure.
- Audience Differential – Was the movie liked more by critics than audiences, liked more by audiences than critics, or liked by both about equally?
- This is captured by the normalized difference between a movie’s Flixster Audience Score and its Rotten Tomatoes Critics Score. All else equal, a large differential skewed towards preference by critics indicates a Secret Success.
- Critical Polarity – When critics didn’t like a film, was it more common to see descriptions like “boring” and “terrible”, or descriptions like “didn’t meet its potential”? The distinction between very negative phrases and more measured phrases ends up being quite useful for distinguishing lame Failures from messy-but-aspirational Fiascoes.
- For this, natural language processing (teaching computers to understand language) was used to programmatically “read” key sentences from Rotten reviews and derive their sentiment – positive, negative, or neutral. The movie is assigned a score based on the frequency of strongly negative statements, from 0 (more negative statements) to 1 (fewer negative statements). All else equal, a higher frequency of negative sentences indicates a Failure.
These three pieces of information “separate” each rating well when making predictions, which is something we can confirm visually.
For instance, in each chart below, the x-axis is the Critical Polarity score. The vertical bars represent the number of films with that rating around each Critical Polarity score. And the line represents the estimated probability of that rating for different values of Critical Polarity, which is what the classifier ultimately uses to help make its decisions. (The three probabilities sum to 1.0 for each value of Critical Polarity.)

At a Polarity score of 0.2 (mostly harsh sentences), for instance, there is a significant probability of a Failure, but quite a low probability of a Fiasco or Secret Success.
Note that even though we are restricting ourselves to Rotten reviews when measuring Critical Polarity, these reviews are still much kinder to Fiascoes than Failures. Once again, the split between Failures and Fiascoes, which are entirely subjective labels that Nathan Rabin came up with out of intuition, can actually be borne out in data.
Having confirmed that these three characteristics of a film separate the different ratings well, we can train a classifier by feeding in the movies from the “My Year of Flops” series, along with these three pieces of information and the movie’s actual rating. When complete, the classifier can guess whether an unknown movie is mostly likely a Secret Success, a Fiasco, or a Failure – and recommend only those movies that are most likely Secret Successes.
How accurate is it? Overall, it works surprisingly well considering what a complex task it’s being asked to mimic: a human reviewer’s thought process.
As a first test of accuracy, the classifier was trained on a part of the MYOF series, and then asked to predict which of the remaining movies were Secret Successes. (Specifically, a Naïve-Bayes classifier was tested via 10-fold cross-validation.) The baseline I measured against was a system where any film with a “Fresh” rating on Rotten Tomatoes was assumed to be a Secret Success. Accuracy was measured by F1 score, which rewards systems that make both accurate recommendations as well as accurate rejections.
The F1 score of the baseline was 0.33; the F1 score of our classifier was 0.65, meaning our classifier represents a significant boost above the baseline of using a movie’s “Fresh” or “Rotten” rating to make recommendations.
The second test of accuracy was making sure the system wasn’t “overfitting” to the training set and could generalize well to new movies. After all, an election forecast can be tested against past elections during development, but the ultimate test is its performance on the real, unseen Election Day; similarly, the ultimate test for our system was to make successful predictions on new films that weren’t part of the training set. To that end, I asked the system to predict ratings for ten movies from Rabin’s follow-on “My World of Flops” series, and only recommend the movies it predicted to be Secret Successes.
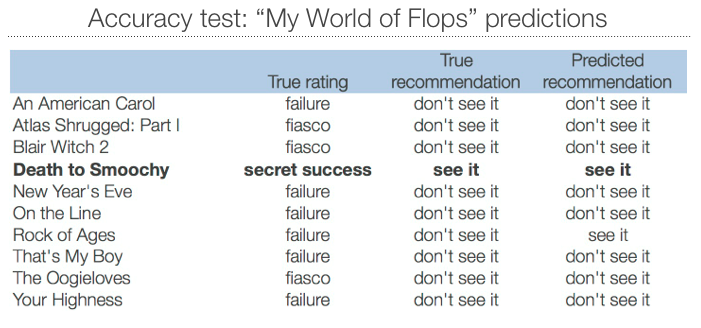
The classifier made accurate recommendations for 9 of the 10 movies, including recommending the only Secret Success in the group (despite its 42% Critics Score on Rotten Tomatoes). This gives us confidence that the patterns found in the MYOF dataset can generalize well to a new list of movies.
TEACHING A COMPUTER TO WATCH AFTER EARTH… SO YOU DON’T HAVE TO.
With the classifier working, I began searching for new “candidates” to feed in and evaluate. As a start, I used data from Box Office Mojo to find movies released between 2003 and 2011 that earned back less than 50% of their budget at the domestic box office. Since I wanted to exclude small films that never saw wide release, I only included films that cost at least $7.5M to produce.
This produced about 250 candidates released between 2003 and 2011. Of that set, about 100 were identified and recommended as likely overlooked films, enough for two years of weekly viewing on your own.
| PREDICTED SECRET SUCCCESSES | PREDICTED FIASCOES AND FAILURES | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
|
There are likely more candidates that can be evaluated; the biggest limitation was finding movies with a known production budget. As a future effort, I may scan IMDb and Wikipedia to find more movies.
And while pleased with this start, I also wonder what additional refinements to the algorithm can be considered.
In particular, a movie like Dirty Work stymied the classifier, continuously coming up as a Failure despite its true Secret Success rating.
The model was never really able to grasp the concept that, yes, Dirty Work can simultaneously be a terrible film and still so damn funny. But while self-driving cars and election predictions are making impressive strides, I don’t know if Bayesian inference will ever be able to square that circle.
(Questions, comments, or suggestions? @ajaymkalia on Twitter or e-mail me at skynetandebert at gmail dot com)
Follow @ajaymkalia
Reblogged this on Music Machinery and commented:
Check out this post by my co-worker @ajaymkalia about how machines can help us discver overlooked films. I’m not sure if Ajay knows about the Shawshankr – http://shawshankr.com/