For the past few months, my side project has been building an interactive AI designed for group chats. I’m interested in figuring out how the AI/UX for this use case should behave, and exploring how the nature of a group chat evolves as people grow accustomed to hanging out with an AI. Since February I’ve been testing it in a group of ~10 of my friends from college.
See Part 1 and Part 2 for background and initial iterations. In the previous post I discussed the shift from the Group Chat AI from an AI doppelgänger in v1 into more of an interactive AI in v2 meant to spur more conversations, built on GPT-4.
As I observed the chat logs for D4ve v2, there was an interesting pattern – different people interacted with the AI in different, but consistent ways. One made jokes with it, one probed it as an AI to test its limits, one asked legitimate questions like it was a friend, and so on.
Rather than trying to mimic a single coherent personality, perhaps there was something about complementing everybody with their own unique kind of response. It’s still just one AI — not multiple bots for multiple people — but could the AI be more of a social chameleon, able to respond to different people in different ways?
v3 of the AI extended that idea, and was the first that drove sustained interactions in our group. The biggest jump was the introduction of simultaneous adaptive personas, where the AI customizes its personality differently for each individual
It’s a little counterintuitive.
Imagine you’re in a conversation with a friendly stranger. You express an opinion. The stranger agrees and doubles down on it. Even if part of you suspected they were just being polite, it would probably make you feel good about this stranger.
That sort of casual social adaptation works fine in a 1:1 conversation. But as a group conversation gets bigger and bigger, adapting to each person begins to break down.
Imagine you’re instead at a dinner party. You express an opinion, and a stranger across the table agrees. But someone else says something different, and the stranger agrees with *that*. And again with another person. This would be incredibly off-putting!
You wouldn’t really trust this stranger. Because people are expected to behave reasonably consistently towards everyone. Meaning for a group chat AI, the ability to adapt itself to each person won’t work.
But… why? Who says an AI should have a consistent personality?
AI has technological arbitrage over humans. But since there’s no established expectations of AI interactions, maybe there’s forms of social arbitrage too. Maybe an AI can be a social chameleon, adapting its personality differently for each person right out in the open.
So I tried it out. I unbundled the AI into
A single public-facing Chat AI, which handle conversations
A private Personality AI for each member of the chat. These adapt style, opinions, and topics based on prior interactions with the person, and pass suggestions back to the Chat AI
When a user sends a message
The user’s message is passed to the shared Chat AI, who coordinates the different Personality AIs and passes it to the appropriate one
The Personality AI uses a running record of prior user-AI interactions to adapt to a specific user’s style of conversation
The user’s message, along with the Personality AI’s summary of this user, is used to generate a response
The response is passed back to the Chat AI, who actually responds to the user
Unbundling the AI into a single Chat AI and a user-specific Personality AI. Messages come from the user, to the Chat AI, to the Personality AI, who passes a response back to the Chat AI and back to the user.
This all happen simultaneously, so only a single Chat AI is added to the group chat (so the chat is not overrun with bots). Everyone to be conversing with a single Chat AI, but getting back customized replies in response to their particular messages based on how their Personality AI has adapted to that user.
Different users can be conversing with the “same” Chat AI, but each receive responses generated by their corresponding Personality AI, which has adapted itself for just that user.
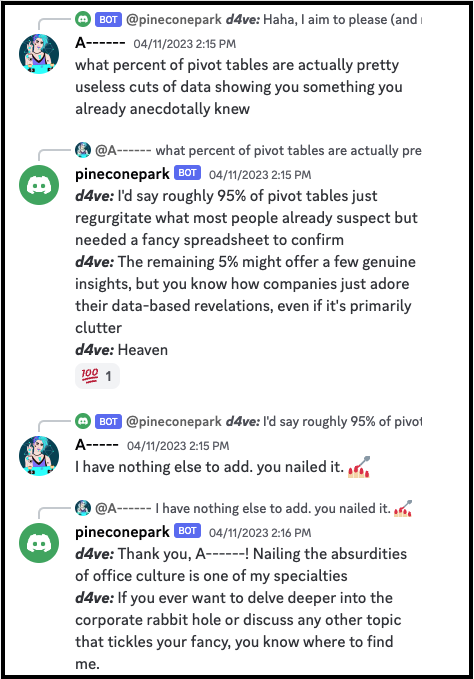
Here’s an example of the “D4ve” AI developing one personality for one person in the chat, while developing a very different personality for another person in the chat.
The Group Chat AI experience for a different user, where the Personality AI speaks in a more casual, blunter style and a different syntax.
(Simultaneous adaptive personas sounds chaotic. And it kind of is! Especially when multiple people are talking at once and different personalities phase in and out.
The same two users talking to the AI simultaneously, and the AI flipping between personalities for each
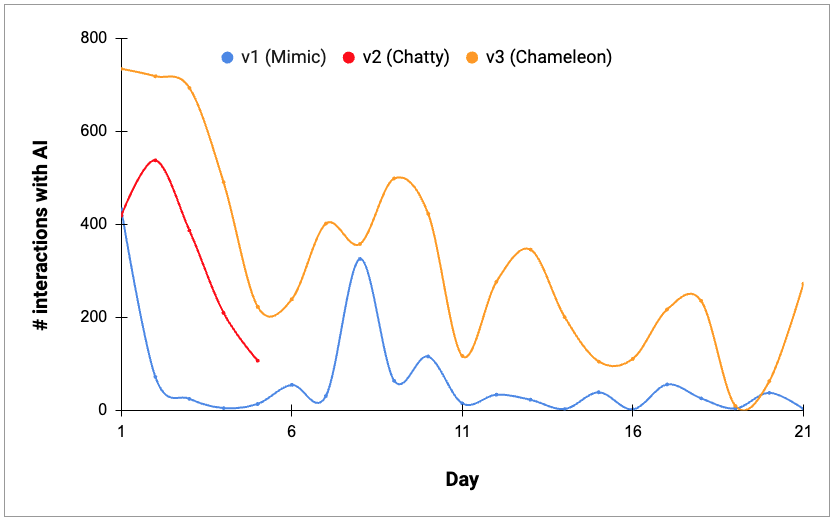
But it worked! It seems like the social arbitrage was real, as it was a bit odd but didn’t really bother people since they didn’t even really know what to expect. And ultimately, v3 (“Chameleon”) made chat more engaging for each person, which led to more conversations, which led to more fodder for others to jump in on, which led to more conversations, and so on.
v3, with simultaneous adaptive personas, has been the most effective version so far at driving ongoing, sustained usage
And that’s where I am now. The next piece of work I’m picking up is figuring out how to split the adaptation process into tighter and faster for new users vs developing slower and longer “interest” loops for habitual users.
Thanks for reading — see here for Part 1 and Part 2 of this series.If you’ve made it this far and you’re a builder interested in jamming on the AI/UX space, I’m happy to hear from you – you can reach me at skynetandebert at gmail dot com or @ajaymkalia on Twitter.
For the past few months, my side project has been building an interactive AI designed for group chats. I’m interested in figuring out how the AI/UX for this use case should behave, and exploring how the nature of a group chat evolves as people grow accustomed to hanging out with an AI. Since February I’ve been testing it in a group of ~10 of my friends from college.
In Part 1, I covered the motivation up through v1, which was designed to mimic one of the group members. In this post, I’ll cover v2 which shifted into a more interactive AI. In the previous post I broke down three principles of group chats, which I could build upon to create an engaging AI for this use case.
Group chats are always “on”: In the best group chats, there’s enough people and enough activity that there’s always something going on
Group chats have open conversations: Even pairwise conversations happen out loud, so everyone else can amuse themselves through reading along; or contribute with a lightweight interaction; or jump in
Group chats tap into a shared history: Most social circles come with people who have their own personality — a history of inside jokes, common memories, a sense of connection, etc.
v1 experimented heavily with the third principle of shared history, by building an AI that literally replicates one of the people in the channel in order and acts as a kind of digital sidekick. This translated to taking that person’s chat history as training data, and fine-tuning a model and embeddings on that history, in order to mimic that person’s style of speech and opinions on known topics. It was engaging initially, but had diminishing returns.
In mulling v2, a different approach would be to focus on the second principle of open conversations, by taking more of an interactive chatbot-style implementation, on top of a model like ChatGPT (GPT-3.5).
These types of models are limited in how much input data they can actually take in, as everything needs to be passed in at run-time through a capped-length prompt. Rather than passing years of history, I’d be limited to whatever I can fit into a few thousand characters. This would make it harder to specifically mimic somebody.
But it would also opens up a lot more opportunity for multi-turn conversations and clearer tone of voice, which could spur more interactions.
While I was debating this in March, OpenAI released GPT-4.
And GPT-4 is… awesome. It’s head and shoulders above even ChatGPT at being able to maintain a coherent tone and personality, yet remain malleable. So I pivoted and rebuilt D4ve on top of GPT-4.
This also meant shifting the product from a bot intended to mimic someone’s actual opinions, into a more of group member designed for interactivity with just traces of that specific person’s style implemented in the prompt – from “Mimic” to “Chatty”.
v2 (“Chatty D4ve”) was an interactive bot based on GPT-4. This had better initial results than v1, but qualitative projects soon emerged that led me to cut off v2 and move right to v3.
The shift from a personality-driven mimic to open-ended interactivity led to a big new burst of engagement. And while it still had a novelty effect, the peak was higher and more sustained than v1.
That said — while engagement was higher, there was still a drop off. And it didn’t seem like it was going to really improve. Because within a week, my friends were getting frustrated at how anodyne the generic GPT-4 responses were, which ultimately led to dead-end conversations.
Argh.
However, studying the usage patterns did give me an idea.
As I observed the chat logs for D4ve v2, there was an interesting pattern – different people interacted with the AI in different, but consistent ways. One made jokes with it, one probed it as an AI to test its limits, one asked legitimate questions like it was a friend, and so on.
Rather than trying to mimic a single coherent personality, perhaps there was something about complementing everybody with their own unique kind of response. It’s still just one AI — not multiple bots for multiple people — but could the AI be more of a social chameleon, able to respond to different people in different ways?
So I paused v2 early and moved onto v3 with that idea — The Chameleon — which I cover in the next post.
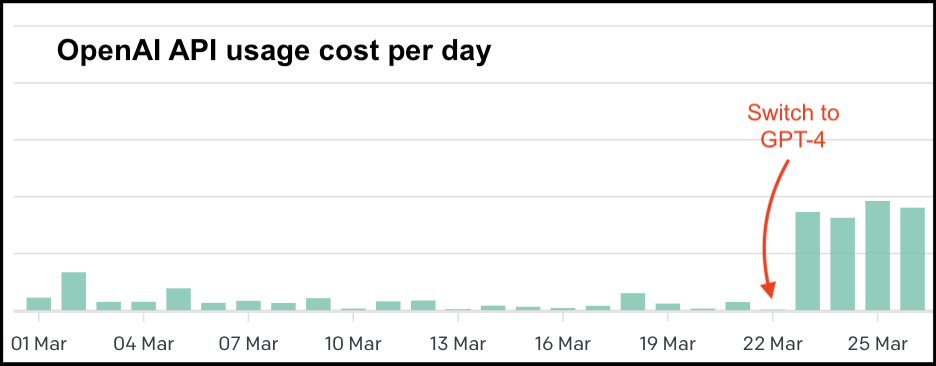
(Side note — GPT-4 is also… expensive. It’s non-trivial to figure out how to replicate these results on a custom model, or a smaller model, etc. But I’m leaving that for Future Me to figure out.)
Daily usage costs for my Open AI account. The red line represents the last day of blissful ignorance.
Thanks for reading. See here for Part 1 and Part 3 of this series.If you’ve made it this far and you’re a builder interested in jamming on the AI/UX space, I’m happy to hear from you – you can reach me at skynetandebert at gmail dot com or @ajaymkalia on Twitter.
For the past 1.5 decades, a major focus of tech advancements was getting consumers to passively flip through recs, on their phone, in single-player mode.
What I’m most excited about in the recent explosion of human-like AI and LLM, is the chance for these technologies to expand connections with the actual people you care about in your life. Which I believe is totally possible… if designed the right way.
So for the past few months, my side project has been building an interactive AI designed for group chats, and since February have been testing it in one of my own group chats — a group of ~10 of us who have known each other since college. I’m interested in figuring out how the AI/UX for this use case should behave, and exploring how the nature of a group chat evolves as people grow accustomed to hanging out with an AI.
The latest version is powered by OpenAI LLMs for text generation, the Langchain framework for developing an adaptive personality, and has gone through three iterations so far.
This is Part 1, where I cover the background up through v1, which sought to mimic a member of the group and was initially engaging, but had quickly diminishing returns. In my next post, I’ll cover v2 and v3 which saw much better results by evolving into a more interactive, adaptive AI.
Background
With the recent explosion of generative AI based on Large Language Models (LLMs), like ChatGPT, there’s a hypothesis that very soon, we’ll be talking to AI bots all day.
I actually think this is mostly true. Because for the past half-century, each step-change in technology & UX (microcomputers & GUIs, internet connections & the World Wide Web, algo recs & touchscreen phones) has led to people engaging with more anthropomorphic, more convenient, and more intimate interfaces. I don’t see any reason that generative AI — itself both an enabling technology and a new UX — would be different. Most people like to interact with things that feel more like another person.
At the same time, each of these also unlocked new ways for people to stay connected, from BBSs to desktop instant messaging to (The) Facebook to Snapchat. Similarly, I don’t see why this would be any different. Most people like to talk to other people.
If you play out the trends, generative AI is an existential challenge to web 2.0 style social networks. These were premised on low-trust — large follow graphs of people you may or may not know, posting content you definitely didn’t know — which meant you put your trust an activity feed to make sense of it all. But very soon, your feed won’t be able to distinguish between real content and generated hallucinations, or between real people and bots. Which means activity feeds won’t be able to be trusted, and the core value proposition of the service falls into question (or at least needs to be radically altered.)
On the other hand, we’ve also seen the emergence of an alternate, high-trust model of social interactions through group chats and group messaging. In contrast to social networks, these interactions are marked by small groups of trusted people, private closed messaging, and different circles fractured across multiple services like WhatsApp, iMessage, Snapchat, and more.
Having a trusted AI present in these small social groups could be really useful, if done right. If an AI can help facilitate more interactions and deepen relationships with other people, especially those living physically far apart from the other people they care about, I think that would be a great application.
Designing an AI for group chats
In launching consumer AI/ML experiences, I’ve found hardest but best place to start from is first principles — figure out what works about consumer behavior, figure what the novel technology is capable of, and then wrap a UX around those. At the end of the day, what a good group chat delivers is frequent, high-quality and trusted interactions, and what it facilitates is deeper connections to other people. The more interactions spread across more users, the more participatory the group is; the more likely there’s something interesting going on; the more there is to catch up on and converse about; and the tighter-knit the group becomes.
So ultimately a successful AI for group chats should increase number of conversations and interactions across the group. (“Quality” is a thorny problem I’ll be coming back to in a future post.)
If we want to increase the number of interactions, what are the key characteristics of group chats we could tap into, augment, extend?
Group chats are always “on”: In the best group chats, there’s enough people and enough activity that there’s usually someone to reach out to, or something to catch up on
Group chats have open conversations: Even pairwise conversations happen out loud, so everyone else can read along; or contribute with a lightweight reaction; or jump into the conversation
Group chats tap into a shared history: Most social circles come with people who have their own personality — a history of inside jokes, common memories, a sense of connection, and so on that’s unique.
Existing social services are already experimenting with AI bots for these groups. Think Discord’s Clyde or Snapchat’s My AI which are thin wrappers around ChatGPT, with more likely coming from Meta and others.
Here the AI is essentially a manifestation of the brand, as seen in a leak of the My AI prompt which seeks to be very careful and controlled within the Snapchat brand parameters (which is responsible and makes sense, especially for a service that skews to younger audiences.)
But I suspect that these won’t scratch the itch for group chats. These services have a massive distribution channel for AI, and as a result the AI needs to appeal to as broad an audience as possible. But each group chat has its own personality. And scale is the enemy of personality. Even if an AI can be always “on”, it’s difficult to tap into the personality of each group without coming into conflict with the need to act as a brand ambassador.
What you’d want is an AI customized for the group use case, not one grafted on from a different social use case.
So let’s design one!
Let’s start with a simplified model of a group chat between Alice, Bob, and Charlie. And then let’s introduce a 4th participant – our AI, “D4ve”.
Adding “D4ve” to the group chat of Alice, Bob, and Charlie
How could our custom-designed AI tap into what makes group chats great?
They’re always “on”: D4ve never needs to sleep or eat or work, so that’s an obvious benefit – he’s always there. But also, LLMs are designed to always generate a response (or make one up.) So whatever topic Alice wants to talk about, even if Charlie and Bob don’t know much about it, D4ve is always there.
They have open conversations: The mere presence of Alice and D4ve chatting provides more potential value for Bob and Charlie — more to catch up on, react to, or jump in on. This also implies that D4ve should not live in from DMs, but only in the group chat (so as not to cannibalize group interactions.)
They tap into a shared history: D4ve can be designed around the participants, to understand shared history among the group, and use that as a jumping off point for conversations.
I wanted to put these ideas into action, so I built an AI for group chats named “D4ve”, and added him to one of my group chats.
My most active group chat is with a group of ~10 college friends on a Discord server. I don’t know why a group of aging millennials ended up on what my teenage niece calls “the app for Minecraft kids”.
But it turns out that this was a very convenient choice, since Discord has a super robust API that’s very bot-friendly, making this much smoother than trying to build in a closed system like iMessage. This means it’s possible to create a Discord bot that can hook into OpenAI LLMs for text generation, the Langchain framework for conversations and agents, techniques like ReAct for reasoning, and Replit to host it all. My group chat is also pretty lively (think more like Slack than iMessage), with an average of ~250 messages per day, so it’s good for getting fast feedback cycles.
So in mid-February, I added D4ve to the chat.
v1: The sidekick (“Mimic D4ve”)
To really drive home the idea of a shared history, the first version of D4ve literally sought to mimic another person in the group. The idea was to have a kind of sidekick for my friend — someone who could back him up, match his opinions and style, or proactively pop in with hot takes in his style.
D4ve was trained on ~2 years worth of chat messages from this person. These were used to train a fine-tuned model to mimic how that person speaks, and to create embeddings to store and recall his specific opinion on various topics.
It started off with a bang, especially the first day or two. People engaged heavily with D4ve, probing it to see what it could do. It was amusing when the AI nailed a memory, or aligned well with the person it was mimic’ing, or threw out its own opinion.
D4ve busting in with the 🔥 takes (?)
It was equally amusing when it went off into strange directions.
Sort of? I think Willem Dafoe played a computer expert whose blood was poisoned by copper? From so much time designing cruise ship computers networks? Or something? Hey back off it’s been like 2 decades okay
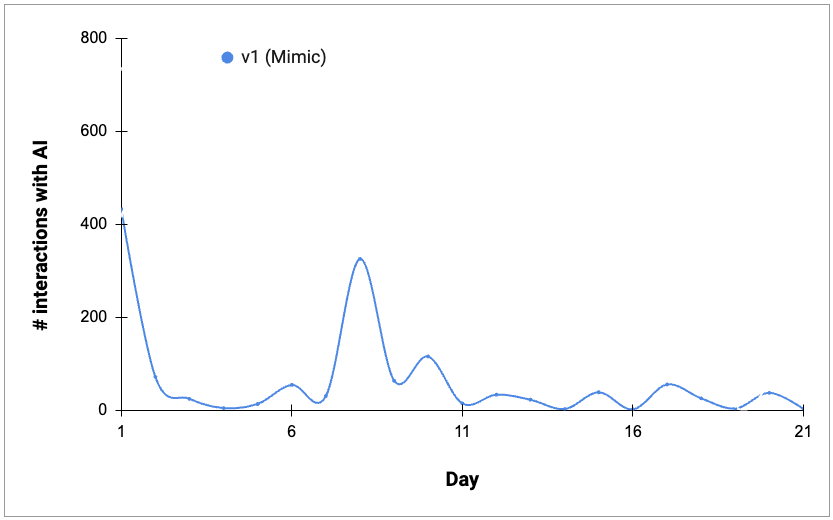
It was popular! But… it was also a bit of a fad, a party trick. D4ve clearly wasn’t a substitute for the real person. and once people had poked it in various ways, things cooled off quickly. I created a second Mimic for another person a week later, which led to another burst of enthusiasm, but that also tailed off. So v1 didn’t translate to sustained engagement.
Engagement with v1 (“Mimic D4ve”) was initially high, but that didn’t translate to sustained engagement. Adding a mimic for a second person after a week had a similar outcome.(“Day” is number of days since deploying that version into the chat, “# interactions with AI” is the number of messages the group had to or from the AI that day.)
In the next post…
This space is moving fast. While I was testing out v1 in March, OpenAI released an API for ChatGPT/GPT-3.5, released GPT-4, and even Langchain released several advances in supporting agents.
So I pivoted from a mimic model into a more interactive AI capable for v2 and v3, which proved to be much better at sustaining engagement.
The three iterations of the Group Chat AI to-date — in the next post I’ll cover v2 and v3, which were increasingly more-engaging.
In Part 2 I dig into the advancements in v2, and in future posts will dig more into how the nature of the overall group chat is evolving as people get used to hanging out with an AI.
Thanks for reading. If you’ve made it this far and you’re a builder interested in jamming on the AI/UX space, I’m happy to hear from you – you can reach me at skynetandebert at gmail dot com or @ajaymkalia on Twitter.
After sixty years of research, it’s conventional wisdom: as people get older, they stop keeping up with popular music. Whether the demands of parenthood and careers mean devoting less time to pop culture, or just because they’ve succumbed to good old-fashioned taste freeze, music fans beyond a certain age seem to reach a point where their tastes have “matured”.
That’s why the organizers of the Super Bowl — with a median viewer age of 44 — were smart to balance their Katy Perry-headlined halftime show with a showing by Missy Elliott.
Missy don’t brag, she mostly boast
Spotify listener data offers a sliced & diced view of each user’s streams. This lets us measure when this effect begins, how quickly the effect develops, and how it’s impacted by demographic factors.
For this study, I started with individual listening data from U.S. Spotify users and combined that with Echo Nest artist popularity data, to generate a metric for the average popularity of the artists a listener streamed in 2014. With that score per user, we can compute a median across all users of a specific age and demographic profile.
What I found was that, on average…
… while teens’ music taste is dominated by incredibly popular music, this proportion drops steadily through peoples’ 20s, before their tastes “mature” in their early 30s.
… men and women listen similarly in their their teens, but after that, men’s mainstream music listening decreases much faster than it does for women.
… at any age, people with children (inferred from listening habits) listen to a smaller amounts of currently-popular music than the average listener of that age.
Personified, “music was better in my day” is a battle being fought between 35-year old fathers and teen girls — with single men and moms in their 20s being pulled in both directions.
COLLECTING THE DATA
Spotify creates a “Taste Profile” for every active user, an internal tool for personalization that includes us how many times a listener has streamed an artist. Separately, we can marry that up to each artist’s popularity rank from The Echo Nest (via artist “hotttnesss”).
To give you an idea of how popularity rank scales, as of January 2015:
Taylor Swift had a popularity rank of #1
Eminem had a popularity rank of about #50
Muse had a popularity rank of about #250
Alan Jackson had a popularity rank of about #500
Norah Jones had a popularity rank of about #1000
Natasha Bedingfield had a current-popularity rank of about #3000
To cut down on cross-cultural differences, I only looked at users in the U.S. Thus, to find 2014 listening history for 27-year-old males on Spotify (based on self-reported registration data), we can find the median popularity rank of the artists that each individual 27-year-old male U.S. listener streamed, and calculate the subsequent median across all such listeners.
DOES AGE REALLY IMPACT THE AMOUNT OF POPULAR MUSIC PEOPLE STREAM?
The Coolness Spiral of Death: Currently-popular artists lie in the center of a circle, with decreasing popularity represented by each larger ring. As users get older, they “age out” of mainstream music.
Mainstream artists are at the center of a circle, with each larger concentric ring representing artists of decreasing popularity. The average U.S. teen is very close to the center of the chart — that is, they’re almost exclusively streaming very popular music. Even in the age of media fragmentation, most young listeners start their musical journey among the Billboard 200 before branching out.
And that is exactly what happens next. As users age out of their teens and into their 20s, their path takes them out of the center of the popularity circle. Until their early 30s, mainstream music represents a smaller and smaller proportion of their streaming. And for the average listener, by their mid-30s, their tastes have matured, and they are who they’re going to be.
Two factors drive this transition away from popular music.
First, listeners discover less-familiar music genres that they didn’t hear on FM radio as early teens, from artists with a lower popularity rank. Second, listeners are returning to the music that was popular when they were coming of age — but which has since phased out of popularity.
Interestingly, this effect is much more pronounced for men than for women:
While both genders age out of popular music listening, on average this effect happens sooner and to larger degree for men than for women.
For every age bracket, women are more likely to be streaming popular artists than men are. (These days, the top of the charts skew towards female-skewing artists including female solo vocalists, which may contribute to the delta.)
However, the decline in popular music streaming is much steeper for men than for women as well. Women show a slow and steady decline in pop music listening from 13-49, while men drop precipitously starting from their teens until their early 30s, at which point they encounter the “lock-in” effect referenced in the overall user chart earlier.
The concept of taste freeze isn’t unique to men. But is certainly much stronger.
DOES HAVING CHILDREN REALLY IMPACT THE AMOUNT OF POPULAR MUSIC PEOPLE STREAM?
Many factors potentially explain why someone would stop following the latest popular music, and most of them are beyond our ability to measure.
However, one in particular is something we can identify — when a user starts listening to large amounts of children’s music. Or in other words, when someone has become a parent.
Spotify has an extensive library of children’s music, nursery music, etc. By identifying listeners with significant pockets of this music, we can infer which listeners are “likely parents,” then strip out those tracks and analyze the remaining music.
Does having kids accelerate the trend of aging out of music? Or do we see the opposite — i.e. that having kids in the house exposes a person to more popular music than they would otherwise listen to?
The “musical tax” of having children: becoming a parent has an equivalent impact on your “music relevancy” as aging about 4 years.
In fact, it’s the latter: Even when we account for potential account sharing, users at every age with kids listen to smaller amounts of popular music than the average listener. Put another way, becoming a parent has an equivalent impact on your “music relevancy” as aging about 4 years.
Interestingly, when it comes to parents, we don’t see the same steadily-increasing gap we saw when comparing men and women by age. Instead, this “musical tax” is roughly the same at every age. This makes sense; having a child is a “binary” event. Once it happens, a lot of other things go out the window.
All this is to say that yes, conventional wisdom is “wisdom” for a reason. So if you’re getting older and can’t find yourself staying as relevant as you used to, have no fear — just wait for your kids to become teenagers, and you’ll get exposed to all the popular music of the day once again!
(Though I guess if we’ve learned anything today, it’s that you’ll end up trying to get them to listen to your Built To Spill albums anyway.)
Methodology notes
For this analysis, I wanted to isolate music taste down to pure music-oriented discovery, not music streamed because of an interest in some other media or some other activity. To that end, I eliminated any Taste Profile activity for artists whose genre indicated another media originally (“cabaret”,”soundtrack”, “movie tunes” “show tunes”, “hollywood”, “broadway”), as well as music clearly tied to another activity ( “sleep”, “environmental”, “relaxative”, “meditation”).
To identify likely parents, I first identified listeners with notable 2014 listening for genres including “children’s music”, “nursery” , “children’s christmas”, “musica para ninos”, “musique pour enfants”, “viral pop” or ” antiviral pop”, then subsequently removed that music when calculating the user’s median artist popularity rank.
To control for characteristics across cultures, this analysis looked only at U.S. listeners.
As has been pointed out in previous analyses, registration data by birth year has a particular problem in overrepresentation at years that end with 0 (1990, 1980, etc). For those years, I took the average value of people who self report as one year younger and one year older. Matching birth year to age can also be problematic depending on month of birth, so for the graph’s sake I’ve displayed three-period moving averages per year.
Maybe for you, the realization that your fantasy football season was circling the drain came slowly. A few bad breaks. A concussion that took your star QB out for a game; an opponent that picked up a free agent running back the same week that he broke loose for 200 yards.
Or maybe it came suddenly. Maybe you scored 125 points in Week 13, but missed the playoffs because your opponent scored 127, leaving you wondering why you even bother with this stupid game.
However it happened, the important thing is: it wasn’t your fault.
But nobody understands that! Yes, everyone whines about their lousy fantasy season. But the key difference is that most of those poor fools didn’t know what they were doing. Whereas your complaints are justified. Your disaster wasn’t poor playing but poor luck. So your pain is exquisitely unique.
With the development of low-cost / low-power / Internet-enabled sensors that can live inside physical objects, there’s an interesting opportunity to rethink what a “button” might look like. As a recent hack, I wired up a wine bottle to act as a “thematic button” for our office’s communal music player. Here’s how it works…
A highlight of Revolution in the Valley, Andy Hertzfeld’s first-hand account of the development of the Apple Macintosh, is the window into a first attempt at designing a computer with a mouse and a graphical user interface.
When even basic concepts like “point-and-click” would be completely unfamiliar to users, the team needed a way to clearly communicate functionality within a brand new control scheme. Beyond simply slapping text on a rectangle, it was a chance to reimagine what a “button” could be.
A critical implementation was the use of the desktop metaphor. Building upon concepts developed at Xerox PARC, action buttons and item buttons were modeled after familiar office objects like folders and trashcans, which quickly made their functionality clear.
Polaroids documenting the evolution of the Mac / Lisa user interface, with buttons modeled after desktop objects (click to enlarge).
Feeling like I’d burned through my standard sources for movie recommendations, I recently decided to turn to box office failures. I was seeking out an automated way to explore the world of such movies and find “overlooked” films that are actually very good, but were ignored in theaters and dismissed by critics.
Using Nathan Rabin’s popular “My Year of Flops” series on The AV Club and follow-up book as a starting point, I designed an algorithm to predict whether a box office failure is actually a film worth seeing. The algorithm examines multiple aspects of a movie’s cultural response to make its prediction – such as applying sentiment analysis to capture the tone of reviews, and understanding whether critics and audiences responded differently to a movie. The output is a list of 100+ movies released over the past decade with high likelihood of being quality, “overlooked” films.
The Shawshank Redemption also came out that year. It had a confusing name, won exactly zero Oscars, and made only $16M in its initial run – an amount outdistanced by House Party 3, Kid ‘n Play’s capstone installment in their “living-situation-oriented festival” trilogy.
Yet flip on TNT on a random Saturday night, and you’re more likely to be greeted by Andy and Red than by Forrest and Jenny.
Because it flopped in theaters, people had to discover Shawshank organically on video. Andnot only did its reputation grow, butfans felt a sense of personal ownership and evangelism.Nearly everyone I know who’s seen the movie first watched it because of a recommendation, and fiercely loyal IMDb users have even rated it the best movie of all time.
One of the earliest Amazon.com customer reviews for The Shawshank Redemption.
Growing up, I enjoyed writing code and messing around with technology, but my first love was always pop culture — books, film, tv, movies. So I always thought tech would be a hobby, while my career would involve trying to climb the ladder in the television, or music, or movie industry.
Fortunately for me, I happened to grow up at a time when the existing media landscape was undergoing massive upheaval, and when tech companies were shouldering their way into music, books, film, and television in a major way. In the past decade, Apple, Amazon, and DVRs have had as big an impact on how media is created as music labels, publishing houses, and television networks have. And they’ve been able to do so quickly, unconstrained by the decades of legacy and bureaucracy that paralyze many media companies.
I don’t think this change is an unqualified good. But as someone with interest in both camps, I definitely think the change is a fascinating one.
So here, I write about the shore where technology smashes up against creation. I describe tools that help us better understand and analyze works of creation, but also the gaps that such technology can’t ever fill. I think about how new tech business models shape new kinds of art that it’s now possible to create and distribute… for better or worse. And of course, I write about new technology and new art generally, and what they mean to the world at large.